







sigmod是计算机科学领域的顶级国际学术会议之一,专注于数据库系统和数据管理技术的研究。作为中国计算机学会(ccf)推荐的a类会议,sigmod与vldb、icde并称为数据库领域的三大顶会,近年来论文接收率维持在20%左右。pku-dair实验室的论文《staleflow: staleness-aware data management for mitigating data skewness in fully disaggregated rl post-training》被sigmod 2027接收。
staleflow: staleness-aware data management for mitigating data
skewness in fully disaggregated rl post-training
作者:, , , , , , , , 。
一、背景
随着大模型预训练收益递减,rl后训练已成为提升模型推理能力的关键手段(如deepseek-r1、openai-o1等)。典型rl后训练包含三个环节:rollout(生成轨迹)、reward(打分) 和 training(模型更新)。近年来的趋势是将三者完全解耦,部署在独立资源上异步执行,以获取更好的可扩展性。
然而,这种全异步架构带来了两个数据层面的“顽疾”:
1. 数据陈旧性:rollout使用的模型版本可能落后于training,导致训练数据“过时”,过大的陈旧性会损害收敛。
2. 数据长度偏斜:轨迹长度天然差异巨大(长尾效应),导致不同rollout实例负载不均,拖累整体吞吐。
现有系统要么严格限制陈旧性(但牺牲了缓解偏斜的灵活性),要么激进处理偏斜(但放任陈旧性无界增长),始终在收敛和性能之间被迫取舍。
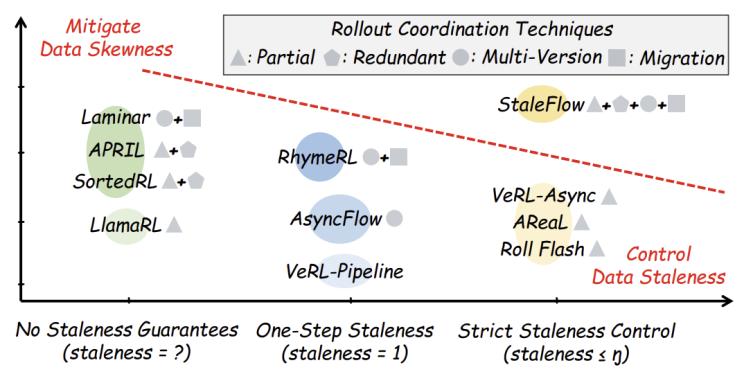
图1. 不同系统在数据陈旧性和长度偏斜处理能力上的trade-off
二、方法
staleflow的核心思想是:从数据管理的底层协议入手,同时控制陈旧性与缓解偏斜,而非在高层做零散的修补。
1. 全局一致性协议:轨迹级的细粒度陈旧性控制
staleflow引入了一个虚拟陈旧性缓冲区(staleness buffer) 抽象,为每条轨迹分配版本标识 ,并通过三个原语 reserve、occupy、consume 追踪轨迹的完整生命周期。缓冲区容量等于batch size,并维护一个缓冲版本 ,严格约束 ( 为用户指定的陈旧性上界)。
该协议不仅轻量(仅记录元数据),而且天然兼容部分rollout、轨迹迁移、组采样、冗余过滤等高级协调技术,使系统在不违反陈旧性约束的前提下,能灵活应对各种偏斜场景。
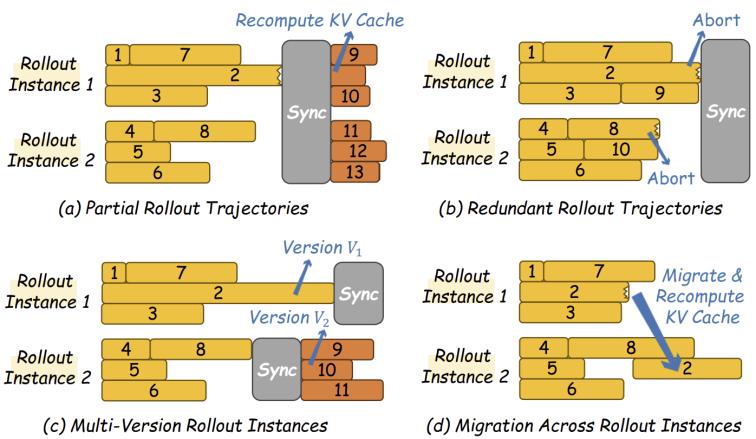
图2. staleflow支持的四种解决数据长度偏斜的技术
2. 解耦式架构:轨迹服务器(ts)与参数服务器(ps)
为了打破原有数据与计算实例的紧耦合,staleflow引入了两个中间件数据服务器:
1)轨迹服务器(ts):存储待生成的初始轨迹和被打断的中间轨迹,由协调器按需路由到各rollout实例。
2)参数服务器(ps):存储最新的模型参数,训练完成后主动推送(push),rollout实例按需拉取(pull)。
通过这种解耦,staleflow可以在实例粒度上独立决定何时拉取新模型、何时中断或迁移轨迹,为灵活的协调策略提供了架构基础。
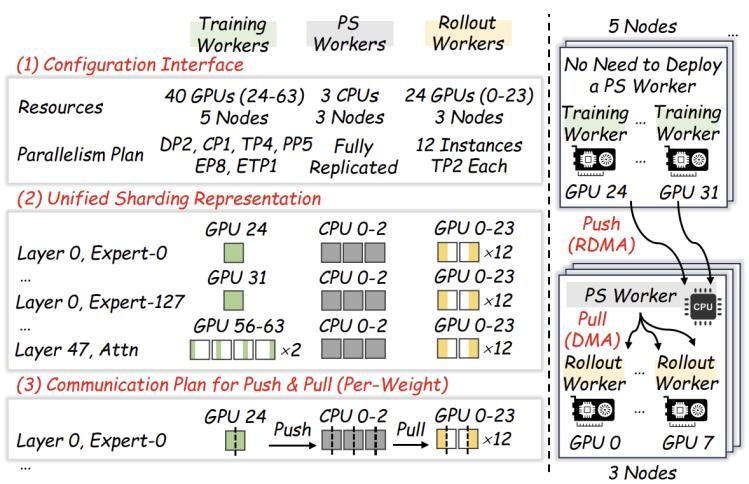
图3. staleflow采用新颖的参数服务器(ps)架构
3. 协调策略:快照-命令循环 成本模型驱动
staleflow的协调器持续执行快照-命令循环:周期性捕获每个实例的kv cache占用、运行轨迹、等待队列、完成数、模型版本等状态,经过推测状态(speculative state) 验证确保决策不滞后,然后依次应用三类策略:
1)路由策略(routing):基于多级队列和瀑布模型,优先处理陈旧度高的轨迹,并选择边际吞吐增益最大的实例进行分配。
2) 同步策略(synchronization):仅当同步能解锁更多路由机会时,才触发模型参数拉取,避免频繁中断。
3) 迁移策略(migration):当等待队列过长或实例间吞吐差距过大时,主动中断并重分配轨迹,重新平衡负载。
这些策略共同作用,使得staleflow能在给定的陈旧性上界内,充分挖掘系统潜力。
三、实验
我们在128张h20 gpu集群上,使用多种模型和dapo算法,与多种基线(同步verl、一步异步verl-pipeline、严格陈旧性控制verl-async/areal/roll flash)进行了全面对比。
吞吐量提升:在所有模型和不同陈旧性上界下,staleflow均取得最高吞吐。相比同步系统,最高提升 2.68倍(平均1.91倍);相比严格陈旧性控制的最优基线,最高提升 1.42倍(平均1.18倍)。增益随允许的陈旧性增大而扩大。
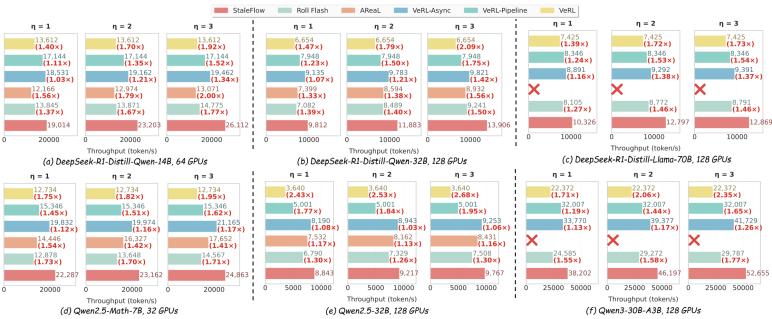
图4. 端到端吞吐
收敛保持:当陈旧性上界小于等于3时,staleflow的奖励曲线和评估准确率与无陈旧性的同步系统基本一致;而当陈旧性上界等于10时训练崩溃,证明了严格陈旧性控制的必要性。
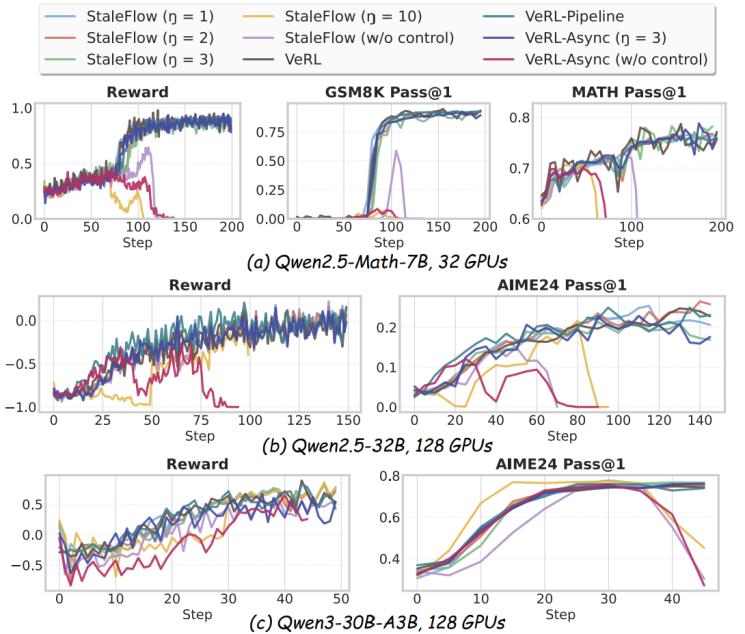
图5. 端到端收敛
可扩展性:在更长响应长度、更大batch size、更多gpu下,staleflow的相对优势愈发明显,表明其缓解长尾偏斜的能力随规模放大而增强。
消融与分解:将路由、同步、迁移策略依次替换为朴素版本,性能逐步下降,全部使用朴素策略时性能接近verl-async,证明增益来源于协调策略的组合效应。开销分析显示,协调命令(route/interrupt/pull)总耗时不到总时间的3%,其中pull参数传输仅占1.7%。
四、总结
staleflow通过引入轨迹级的一致性协议,从根本上解决了陈旧性控制的灵活性问题,使得上层协调策略不再受缚于僵化的约束。此外,staleflow将数据(轨迹和参数)与计算实例解耦,并配合集中式协调器进行全局、实时的吞吐导向决策,能够在不牺牲收敛的前提下,有效应对动态的负载偏斜。实验结果表明,staleflow相比当前广泛使用的rl后训练系统verl,最大提升高达 2.68倍。
北京大学数据与智能实验室(data and intelligence research lab at peking univeristy,pku-dair实验室)由北京大学计算机学院崔斌教授领导,长期从事数据库系统、大数据管理与分析、人工智能等领域的前沿研究,在理论和技术创新以及系统研发上取得多项成果,已在国际顶级学术会议和期刊发表学术论文200余篇,发布多个开源项目。课题组同学曾数十次获得包括ccf优博、acm中国优博、北大优博、微软学者、苹果奖学金、谷歌奖学金等荣誉。pku-dair实验室持续与工业界展开卓有成效的合作,与腾讯、阿里巴巴、苹果、微软、百度、快手、中兴通讯等多家知名企业开展项目合作和前沿探索,解决实际问题,进行科研成果的转化落地。

评论 0