







第30届“acm操作系统原理大会”(sosp: acm symposium on operating systems principles)于2024年11月4日至6日在美国的德克萨斯州召开。sosp与osdi并称为计算机系统领域两个最高水平的学术会议,拥有50多年的悠久历史。本次sosp大会共有248篇论文投稿,43篇被接收,录用率仅为17.3%。

pku-dair实验室论文《enabling parallelism hot switching for efficient training of large language models》被计算机系统领域顶级会议sosp 2024录用,论文介绍了新型的支持并行热切换的大模型训练系统,系pku-dair实验室自研分布式深度学习系统河图hetu(https://github.com/pku-dair/hetu)围绕大模型训练的新成果。


论文介绍
关键词
distributed training
large language model
parallelism strategy
1、导读
近年来,以chatgpt为代表的大语言模型(large language model, llm)引起了广泛的关注,它的性能提升得益于模型参数量、上下文和数据量的增长,同时也给系统优化带来了更多的挑战。现有系统通常假设工作负载是恒定的,从而采用静态的并行策略组合来进行大规模的分布式训练。然而,真实数据集的序列长度在不同样本间差异较大,且大多呈长尾分布,本工作首次揭示了在这类长短文混训的动态场景中,现有系统的静态并行策略会大大拖慢短序列的训练效率。
针对该问题,我们基于自研的分布式深度学习系统河图hetu,创新性地提出了首个支持并行热切换的hotspa系统,通过对mini-batch内的序列进行分组并使用不同的并行策略来最大化训练效率。hotspa利用热切换技术完成模型权重、梯度在策略间的高效转换和累积,在保证精度无损的前提下,最大化利用硬件内存和计算资源。实验结果表明,与megatron-lm、deepspeed等使用静态并行策略的系统相比,hotspa在不同规模的llama2模型和不同上下文长度下,可以获得2.99x的加速比。
2、背景和挑战
近年来,大规模预训练模型得到了快速的发展,它的性能提升得益于模型参数量、上下文和数据量的增长,同时也给系统优化带来了更多的挑战。现有的分布式训练系统提出了一系列并行策略,从而能够在多个设备中处理大规模的模型和数据。并行策略的选择取决于如显存占用、计算开销、通信代价等工作负载,现有的方法通常假设工作负载是恒定的,因此在训练过程中会使用静态的并行策略组合。然而,在真实数据集中,不同样本间的序列长度差异较大,导致了样本间工作负载的不均衡,即使在一个mini-batch内部,这样的现象也是相当显著的,因此现有系统的静态并行策略并不是最优解。
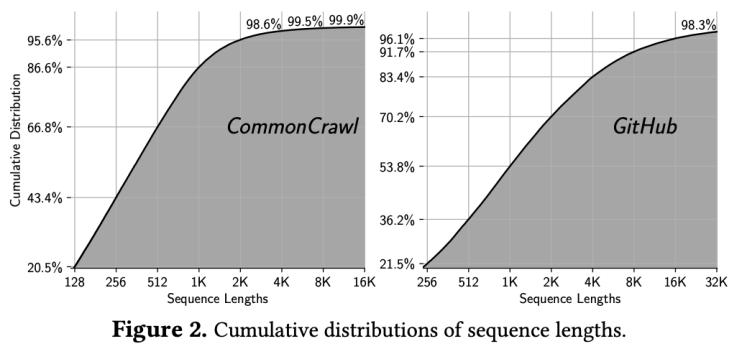
为了支持较长序列的训练,通常需要采用更节省内存的并行策略以避免内存溢出。然而,对于短序列来说这类并行策略会引入大量不必要的通信开销,导致效率低下。结合commoncrawl和github这两个数据集的序列长度分布可以发现,虽然数据集中都包含长序列,但占比不高,以张量并行为例,可以看到随着上下文的增加,需要增大tp以避免oom,但与此同时,对于在数据集中占比大多数的短序列来说,更高的tp意味着更低的吞吐,从而拉低了整体的训练性能。
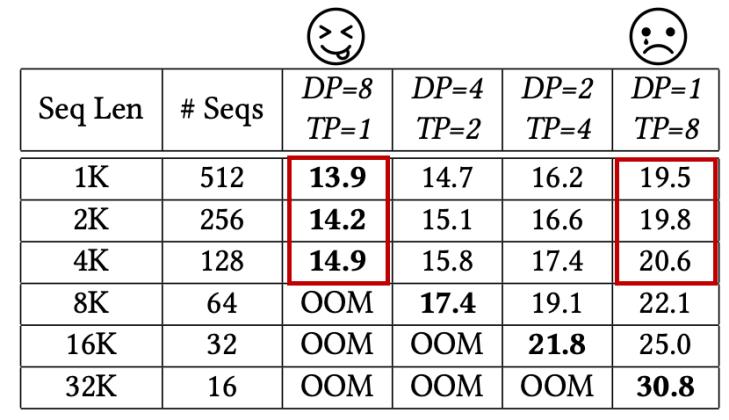
总的来说,现有系统忽视了大模型训练中样本间工作负载不均衡的问题,只是简单地使用静态并行策略来处理。因此,我们尝试从一个尚未被探索的方向来加速模型训练过程:我们能否针对不同工作负载/序列长度的序列采用不同的并行策略?
3、hotspa技术方案
方案概览
根据上述发现,我们提出了hotspa,一个支持并行热切换的训练系统,核心贡献如下:
(1)首次提出并行热切换的训练范式:我们提出了一个基于并行热切换的全新训练范式,对每个mini-batch内的数据,我们会根据其工作负载的差异进行分组,并对每个分组使用最合适的并行策略,在任意两组策略之间,我们的系统都会对模型参数和梯度进行自动、高效且无感的切换,并在模型更新前完成不同策略间的梯度累积,以保证训练效果不受影响。
(2)统一的计算图表示和编译:现有的系统,如megatron-lm和deepspeed,由于其复杂的系统设计,在训练过程中仅支持一种固定的并行策略组合,从而无法对不同的序列负载使用不同的并行策略。而我们的工作设计了专门的图编译器(graph compiler),能够用一张统一的逻辑图同时表示多组不同的并行策略组合,并进一步编译生成对应的多组可执行计算图,共享模型状态的存储,从而才能支持复杂的并行热切换语义。
(3)并行热切换技术:给定任意两组不同的并行策略组合,它们之间的热切换需要在不同的设备中交换模型的参数和梯度,不可避免地会引入额外的通信开销。为了解决这个问题,我们设计了热切换规划器(hot switch planner),提出一种启发式算法来寻找任意两组策略之间的最优通信方案,并引入了一系列通信和显存拷贝的优化技术来进一步降低切换开销。
(4)hotspa系统基于graph compiler和hot switch planner,通过支持并行热切换的训练范式,与现有系统相比,可以获得2.99x的加速比。
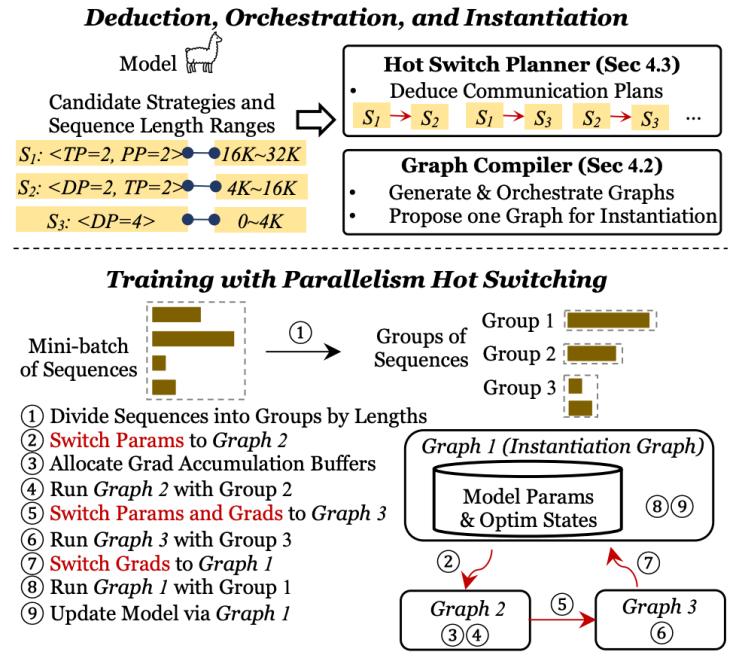
图编译器(graph compiler)
图编译器(graph compiler)支持用一张统一的逻辑图同时表示多组不同的并行策略组合,并进一步编译生成对应的多组可执行计算图,且共享模型状态的存储。对应三个核心步骤:
(1)逻辑图(logic graph):用统一的逻辑图来表示多组不同的并行策略组合。
基于dtensor(distributed tensor, 分布式张量)架构,用dstates(distributed states, 分布式状态)来表示一组并行策略组合:用splits, partial, duplicate来表示参数在不同设备中的切分方式,用devicegroup来表示不同的参数切片和设备的映射关系。
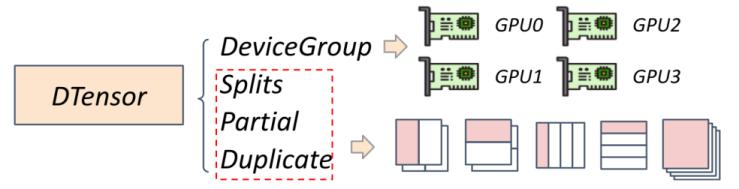
用dstates表示并行策略
为了同时表示多组分布式策略,本工作创新性地将一个dtensor与多组dstates绑定,并支持在整张计算图上同时进行多组分布式状态的推导。具体来说,令每个参数和输入变量都同时绑定多组dstates,并在构建逻辑计算图的过程中,每个算子都会同时对这多组dstates进行推导,并自动插入中间算子以保证功能的完整性。
由于不同的并行策略组合,通过推导dstates所得到的计算图并不一定相同(如下图step1)。为了能够用同一张计算图表示这多组策略,会通过自动插入空算子(dummy op)来处理不同策略在通信等中间算子上的差异(如下图step2)。
通过上述方案,本工作支持了用统一的逻辑图来表示多组不同的并行策略组合。
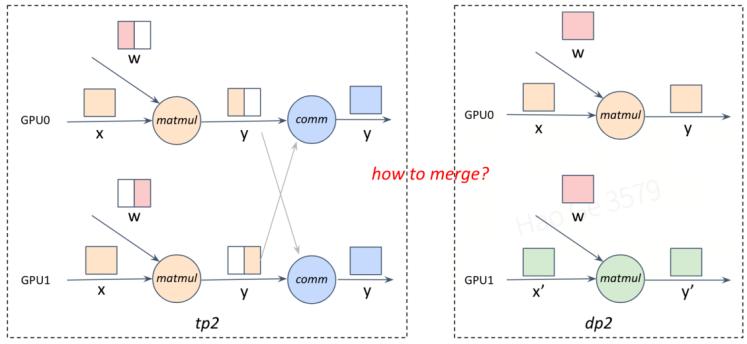
step1:两组不同的并行策略,对应两组不同的计算图
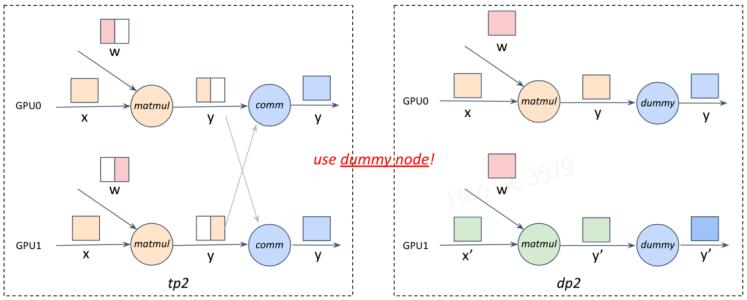
step2:通过引入dummy op,使得两张计算图的表现形式一致
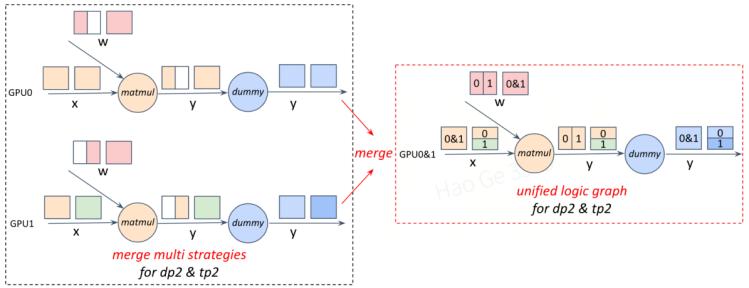
step3: 将两张计算图用同一张逻辑图来统一表示
(2)可执行图(exec graphs):基于统一的逻辑图编译、生成多组可执行计算图,每组可执行计算图都对应一组独立的并行策略组合,它们之间共享同一份模型状态存储。
逻辑图只是一种抽象表示,为了能够编译、生成真正可执行的分布式计算图,编译器会进行算子的插入、合并、剪枝、替换、重排等操作:
- 插入fp32->bf16的类型转换算子、梯度累积算子。
- 合并相邻的comm op和fusion op。
- 剪枝不必要的dummy op和类型转换、梯度累积、梯度通信算子。
- 替换所有的comm op,生成对应的集合通信算子或点对点通信算子。
- 重排计算图局部拓扑,实现计算和通信的重叠(overlap)。
下图给了将一个逻辑图转化为两组可执行图(两组并行策略组合)的具体例子:
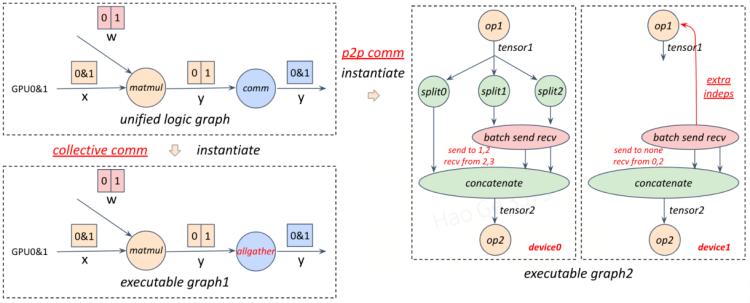
逻辑图(左上角):编译、生成两组可执行计算图(左下角,右侧)
(3)编排可执行图(orchestrate exec graphs):基于hot switch planner给出的代价分析,编排这些可执行图(并行策略组合)的执行顺序,以最小化存储和通信的开销。
选取初始化图(instantiation graph):选取最小化模型状态(model states)存储的策略对应的可执行图作为初始化图。(以下图为例,选取tp2,pp2为初始化图)
重排可执行图(executable graph):基于hot switch planner给出的任意两组策略间热切换的代价,确定不同策略执行的先后顺序,以最小化整体的热切换代价。(以下图为例,tp2pp2->dp4->dp2tp2,只有第一次热切换需要引入额外的通信代价,其余只需要本地切分即可)
剪枝&梯度累积:除初始化图之外,其余可执行图需要剪枝不必要的类型转换算子(type casting op)、参数更新算子(update op)等,从而保证只在初始化图上做模型的更新,在其他可执行图上仅作梯度累积,确保模型的精度不受影响。
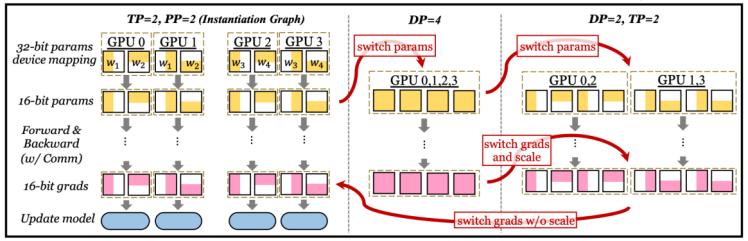
选取tp2,pp2为初始化图,重排可执行图顺序为:tp2,pp2->dp4->dp2,tp2
热切换规划器(hot switch planner)
hotspa支持将一个mini-batch内的数据按照序列长度进行分组,每组采用不同的并行策略(对应不同的可执行计算图),不同策略的梯度会累积到同一个梯度缓冲区(grad buffer)中以保证模型收敛不受影响。
在两组不同的并行策略之间,hotspa会自动对模型的权重和梯度进行热切换,而热切换规划器(hot switch planner)的核心作用就是推导出任意两组不同的并行策略之间切换代价最小的通信方案,具体来说,分为以下2个核心步骤:
(1)基于启发式算法建模热切换(model hot switching)
通信方案存在多个可行解:热切换指分布式状态的切换(从初始策略->目标策略),需要在整个集群中对模型的参数和梯度进行重新划分,是一个多对多的复杂通信,由于数据并行的存在,同一个模型切片在不同设备中存在多份重复的拷贝,对应的发送方并不唯一,因此对于通信方案来说存在大量的可行解。
通信的基本单位-模型切片:对于任意一个模型参数或梯度来说,整体可以看作是一个全局的抽象的paramblock。每个paramblock会根据并行策略所对应的分布式状态被划分成多个paramslice,由于数据并行的存在,同一个paramslice可能被多个设备同时拥有。对于任意两组并行策略(如下图中的src策略和dst策略),它们对paramslice划分的交集,被定义为热切换通信的基本单位-模型切片。
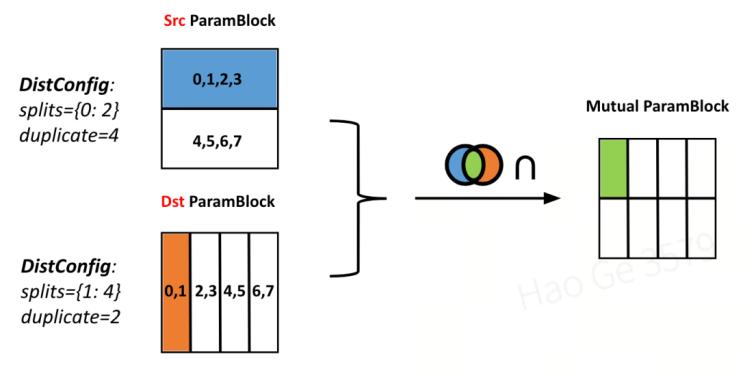
通信的基本单位:两组并行策略对paramslice划分(左侧)的交集(右侧)
热切换问题定义:假设从当前策略热切换到目标策略,则对任意一个模型切片,遍历目标策略中需要该切片的每个设备(needed devices),并从当前策略中拥有它的所有设备里(owned devices)选择最合适的发送方。
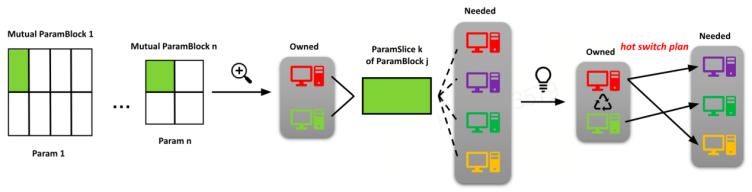
启发式算法:基于两个基本原则,我们提出了一种启发式的搜索算法,从而能够寻找最合适的热切换通信方案。
- 原则一:节点内通信优于节点间通信。在传统的gpu集群中,节点内的gpu是通过nvlink进行链接通信的,相比于节点间走infiniband或以太网的跨机通信,具有更高的通信带宽。因此,如果存在机内或机间等多个不同设备拥有同一个模型切片,则优先考虑节点内的设备作为发送方。
- 原则二:gpu的连接链路是全双工的。现代的网络链接对于数据的发送和接收通常具备独立的通信带宽,因此对于任意设备来说,同时进行数据的收发并不会影响通信效率。事实上,由于每个设备需要接收的数据量是固定的(由切换的目前策略决定),不可能减少,只可能让不同设备的数据发送量尽可能负载均衡。即最小化所有设备的数据发送量中的最大值。

基于上述两个基本原则,热切换通信方案推导的启发式算法流程如下:
- step1: 对每个设备device i,记录机内通信量vi(intra)和机间通信量vi(inter).
- step2: 遍历每个模型参数/梯度切片 slice,基于当前策略和目标策略的分布式状态来确定拥有该切片的设备集合s(owner devices),和需要该切片的设备集合d(target devices).
- step3: 遍历集合d中的每个设备dst,根据机内和机间的差异将集合s中的设备划分为s(intra)和s(inter),基于原则一,优先考虑机内设备s(intra),如果为空,则考虑机间设备s(inter).
- step4: 基于原则二,从候选的设备集合中,贪心地选取当前数据发送量最小的设备作为模型切片的发送方,即src ← arg mini {vi (intra) or (inter) | i∈s(intra) or (inter)};同时更新该发送方对应的通信量,即vsrc(intra) or (inter) ← vsrc(intra) or (inter) sizeof(slice).
(2)优化热切换开销:message fusion & layout optimization
热切换不可避免地会带来额外开销,包括通信开销和显存拷贝开销,这里利用消息合并(message fusion)和布局优化(layout optimization)这两项技术进行专门优化。
消息合并(message fusion):将发送给同一个设备的数据都合并到连续的发送缓冲区(send buffer)里,同理,将从同一个设备接收的数据合并到连续的接收缓冲区(recv buffer)里,从而能够合并多个p2p send/recv,减少p2p kernel的调用次数,还能增大单次通信的数据量大小,提高带宽利用率和通信效率。此外,通过nccl提供的batchedsendrecv原语,支持不同的send/recv buffer对应的p2p send/recv并行传输。
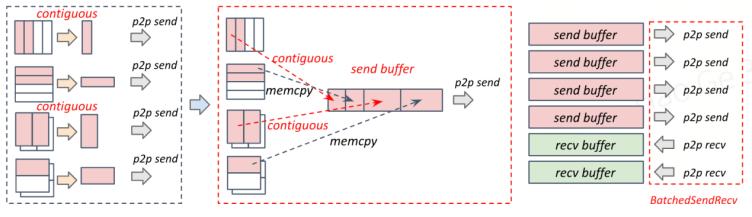
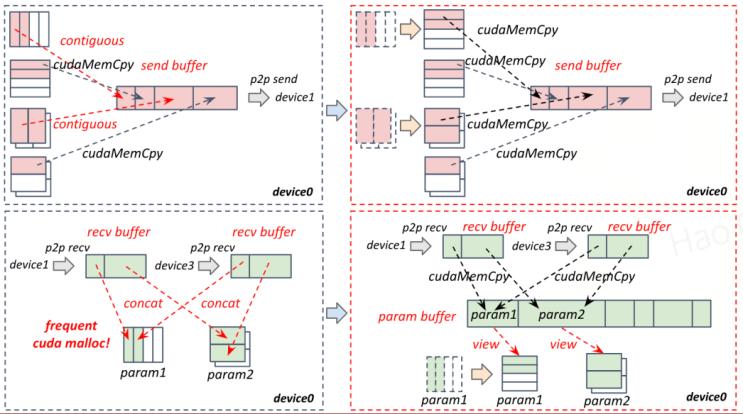
布局优化(layout optimization):为了避免引入contiguous算子和concat算子导致用kernel进行访存和数据搬运,引入过高的拷贝开销,这里将纵向切分的权重/梯度在布局上也按照横向切分排布。此时大部分的非连续的内存访问都可以转化为连续的内存访问,从而可以将大部分比较耗时的contiguous算子和concat算子直接转化为访存代价非常小的cudamemcpy。具体计算时,只需要将改变gemm kernel的layout参数即可保证数学上的等价性。
4、实验效果
hotspa是首个支持并行策略动态热切换的大模型分布式训练系统,相比现有的只支持静态并行策略的系统(如megatron-lm,、deepspeed),hotspa能更灵活地支持和适应负载动态变化的场景,在现有的大多数长短序列分布不均衡的数据集中,能够获得更高的训练吞吐。
实验设置:在实验中,我们将hotspa和现有的两个分布式训练系统megatron-lm(dp tp pp sp)、deepspeed(zero1/2/3 ulysses)在不同负载下进行了比较。在实验环境上,使用4台gpu服务器,每台服务器上有8张a800-80g,机内nvlink的通信带宽为400gb/s,机间ib通信带宽为200gb/s。在模型上选用了开源的llama2,包括三种不同规模的参数量:7b、13b和32b。在数据集上选择了两个开源且被广泛使用的数据集commoncrawl和github。
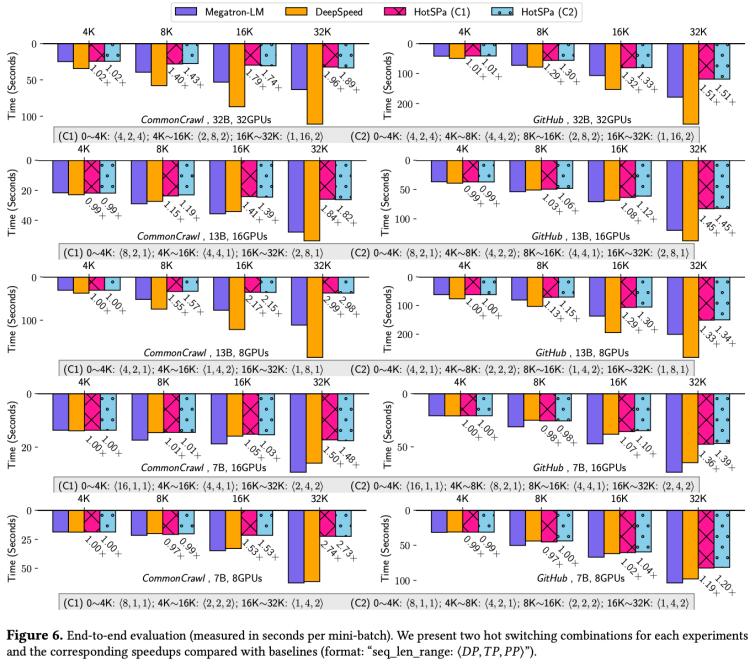
端到端实验:在gpu数量为8卡~32卡,模型规模为llama2-7b~32b,最大序列长度为4k~32k的不同规模上进行实验,在github和commoncrawl两个数据集上,hotspa相对于megatron-lm分别取得最多1.5x和2.99x的加速比,相对deepspeed分别取得最多2.6x和5x的加速比。
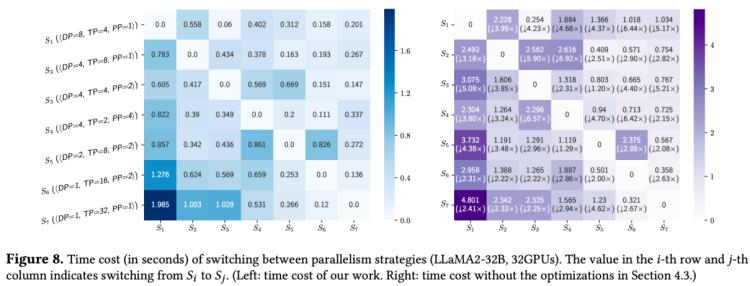
热切换代价实验:以llama2-32b在32卡gpu上的测试结果为例,单次热切换的时间开销基本可以被优化至1s以内,相对于单个step的训练时间,热切换代价占比可以被忽略不计。
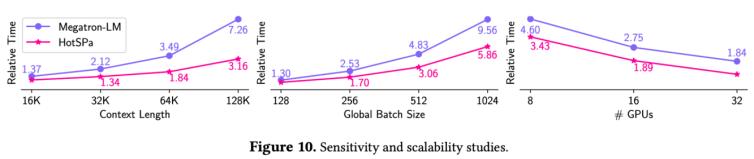
可扩展性实验:context length: megatron-lm的短序列被迫使用长序列的并行策略,因此上下文长度越长,hotspa的加速比越大。gbs: megatron-lm的时间基本随全局批次大小线性增长,而对hotspa性能表现更优,因为随着长序列数量增加,对应分组的pp bubble减少,会进一步获得加速。gpus:两个系统都具有良好的扩展性。
5、结语
在这个工作里,我们首次提出现有框架的静态并行策略不适用于输入序列长短变化的动态场景的缺陷,并创新性地搭建了一套支持热切换训练系统hotspa。hotspa实现于pku-dair实验室自研的分布式深度学习系统-河图hetu(https://github.com/pku-dair/hetu)。除了性能上的优势,hetu还有其他系统所不具备的高动态性和高灵活性。目前我们的系统已经全面开源,欢迎大家关注!

北京大学数据与智能实验室(data and intelligence research lab at peking univeristy,pku-dair实验室)由北京大学计算机学院崔斌教授领导,长期从事数据库系统、大数据管理与分析、人工智能等领域的前沿研究,在理论和技术创新以及系统研发上取得多项成果,已在国际顶级学术会议和期刊发表学术论文100余篇,发布多个开源项目。课题组同学曾数十次获得包括ccf优博、acm中国优博、北大优博、微软学者、苹果奖学金、谷歌奖学金等荣誉。pku-dair实验室持续与工业界展开卓有成效的合作,与腾讯、阿里巴巴、苹果、微软、百度、快手、中兴通讯等多家知名企业开展项目合作和前沿探索,解决实际问题,进行科研成果的转化落地。

评论 0