







ppopp(principles and practice of parallel programming)是并行与高性能计算领域的ccf-a类国际会议,关注并行程序设计、系统与运行时等研究方向。第31届“acm sigplan并行编程原理与实践研讨会”(acm sigplan symposium on principles and practice of parallel programming, ppopp '26)将于2026年1月31日至2月4日在澳大利亚悉尼召开,本次会议从280篇投稿论文中接收51篇,接收率为18.2%。pku-dair实验室论文《elastic and efficient model partitioning and checkpointing for fault-tolerant distributed training》被接收。
elastor: elastic and efficient model partitioning and checkpointing for fault-tolerant distributed training
作者:xuanyu wang,fangcheng fu,haoyang li,hao ge,sheng lin,jiawen niu,bin cui
代码链接:https://github.com/pku-dair/hetu
一、 背景
大模型训练离不开分布式:数据并行(dp)负责扩吞吐,张量并行(tp)/流水并行(pp)负责把超大模型拆到多张gpu上。但现实世界的集群并不“理想”:gpu宕机、节点掉线、网络故障会让可用gpu数量在训练中波动。如果系统只能按“整节点失败”去设计,一旦出现“部分gpu不可用”,要么浪费仍然健康的gpu,要么被迫长时间停机等待。
更麻烦的是,训练策略一变(例如从32卡变成28卡、pp stage数和tp组大小都发生变化),检查点也随之变得难处理。很多框架按“当前并行策略切分参数”来存储权重,恢复时如果切分方式不同,就会出现冗余读取与重分片开销,在共享文件系统(如nas)上尤其致命——i/o调用次数多、单次i/o延迟高,恢复速度很容易被拖垮。
《elastor: elastic and efficient model partitioning and checkpointing for fault-tolerant distributed training》聚焦于以上两个问题:”当gpu/节点在训练过程中失效、可用gpu数量发生变化时,如何既能快速恢复训练,又不把时间浪费在反复的检查点保存/加载与重分片上”,并提供了创新的协同设计凯发备用网址的解决方案:一方面让模型切分足够弹性,能在任意数量gpu上恢复;另一方面让检查点足够“策略无关”,尽量避免因为切分变化而产生重复i/o,并把周期性检查点的额外开销隐藏到训练流水线里。
二、方法
elastor的核心可以概括为四件事:弹性切分(hmp)、策略搜索、细粒度检查点、以及训练-保存的重叠优化。
1. 异构模型并行(hmp, heterogeneous model parallelism):当某些gpu失效时,系统仍能用剩余gpu继续训练。hmp允许不同dp rank内的tp组大小不一致,并在此基础上组织pp阶段与通信组,从而适配“非整除”的gpu数量。
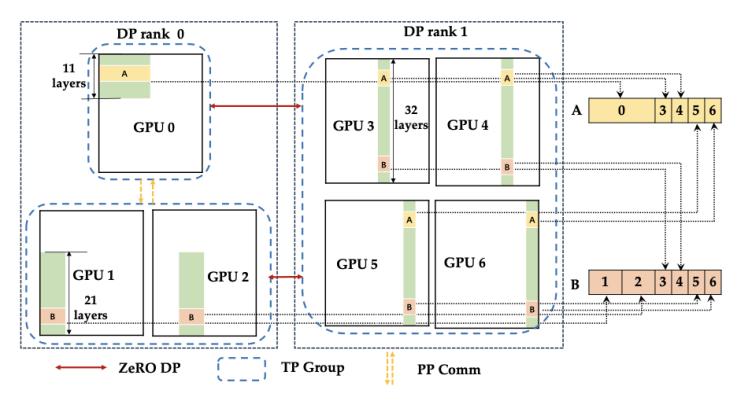
图1:异构模型并行切分方案
2. 恢复时的策略搜索(strategy searching):当gpu数量变化后,elastor会在候选的{dp, tp_max}组合中搜索合适的并行策略。其流程包含:①把可用gpu划分成若干tp组并分配给各dp rank;②在每个dp rank内部进一步决定层/数据如何分配,并通过微批(micro-batch)分配平衡不同rank的计算。在论文的模拟中,策略搜索在1024张gpu规模下也能在数秒内完成。
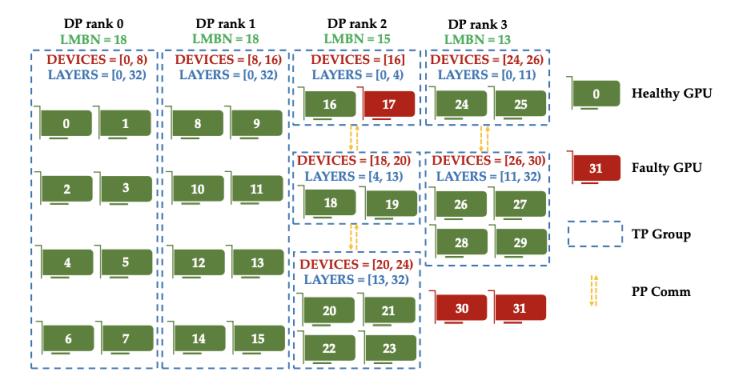
图2:自适应策略搜索示意图
3. 细粒度、分片驱动的检查点(fine-grained checkpointing via splits):将参数张量统一切成全局的global_split份(split),并保证任意hmp策略下每张gpu都持有整数个split。这样恢复时每张gpu只需要加载“自己负责的split”,避免了因切分变化导致的冗余读取。同时,elastor用json元数据记录split与文件位置的映射,做到策略变化下仍能精确定位所需数据。
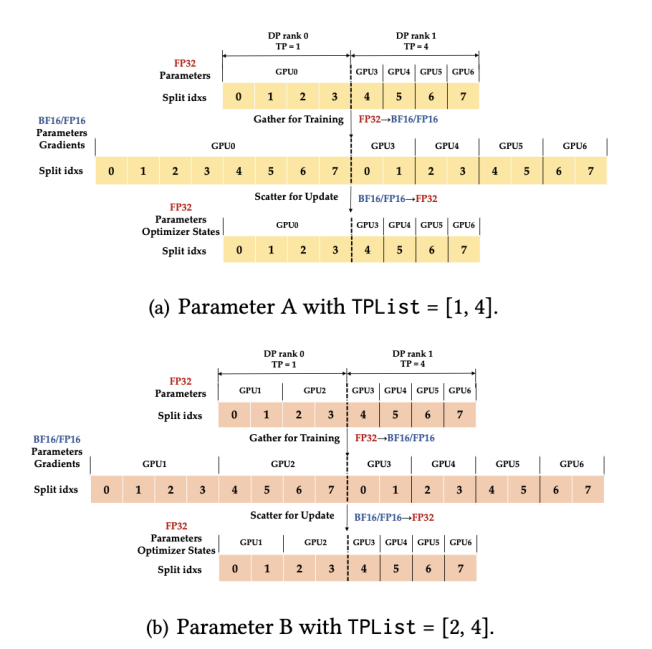
图3: 细粒度,自适应模型切分
4. 高效保存/加载与重叠(overlapping training & checkpointing):保存过程被拆成gpu→cpu内存与cpu内存→文件系统两段,通过共享内存与多进程/多线程把参数搬运、序列化(safetensors)和写盘解耦,并与训练计算流并行执行,尽量把检查点成本“藏起来”。加载阶段则通过重排与合并i/o,把大量小i/o尽可能合并为更少的顺序读取,降低共享文件系统上的开销。
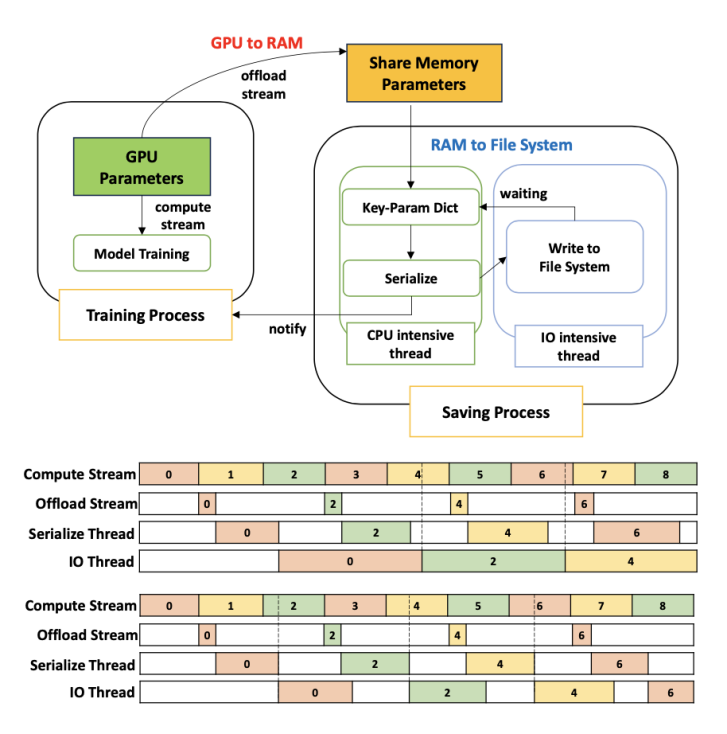
图4: 高效的异步存储方案和流水线
三、实验
论文在32张a100-40g的集群上评估elastor:4台服务器每台8卡,机内nvlink带宽约600gb/s,机间infiniband带宽约200gb/s。文件系统使用nas,单文件写入带宽约800mb/s、读取约1800mb/s,总带宽超过5tb/s。
工作负载选择了3个llm:llama2-7b、llama2-13b与qwen2.5-32b;默认上下文长度4096,全局batch size为256。为了贴近真实环境,作者根据集群故障统计构造了5种gpu可用性轨迹(case a-e),包括单gpu故障、多个节点内gpu故障、整节点掉线/断网、以及混合故障等。
对比基线主要包括:fsdp2 pytorch distributed checkpoint(dcp),以及megatron配合不同检查点方案(如mcp与bcp)。实验从三个维度评估:训练效率、模型加载效率、以及模型保存效率。
- 训练效率:在无故障(case a)下,elastor与强基线训练效率接近;当gpu数量动态变化(case b-e)时,elastor能更稳定地维持mfu,并在端到端训练时间上取得约1.12×–1.40×的加速。
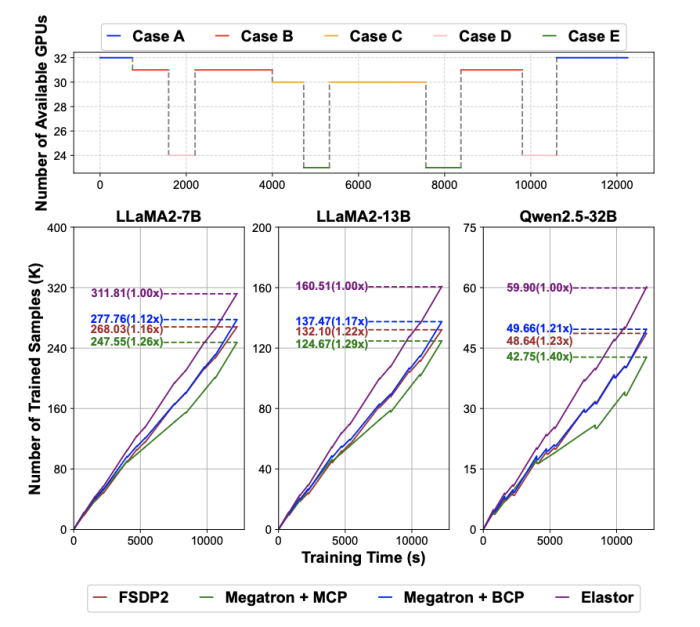
图5: 训练效率
- 加载效率:由于检查点对并行策略更“无关”,且i/o合并更充分,elastor在不同故障场景下的加载耗时显著降低,整体可达约1.95×–4.98×的加速。
- 保存效率:通过训练-保存流水线化与线程解耦,模型保存阶段也获得约1.62×–3.94×的提升,降低了周期性检查点对长期训练的侵蚀。
四、总结
elastor把“弹性训练”往前推进了一步:不再只假设整节点失败,而是正面面对更常见的部分gpu不可用。它通过hmp让模型切分能适配任意gpu数量,又通过细粒度split把检查点做成策略无关,避免了恢复时的冗余i/o与重分片;最后再用重叠与i/o合并把检查点成本压到更低。
对工程实践而言,这篇工作有两个启示:一是故障恢复能力要与并行策略的动态变化绑定考虑;二是检查点格式与加载路径的设计,往往比“写不写检查点”本身更决定系统能否在真实集群里跑得稳、跑得快。
北京大学数据与智能实验室(data and intelligence research lab at peking univeristy,pku-dair实验室)由北京大学计算机学院崔斌教授领导,长期从事数据库系统、大数据管理与分析、人工智能等领域的前沿研究,在理论和技术创新以及系统研发上取得多项成果,已在国际顶级学术会议和期刊发表学术论文200余篇,发布多个开源项目。课题组同学曾数十次获得包括ccf优博、acm中国优博、北大优博、微软学者、苹果奖学金、谷歌奖学金等荣誉。pku-dair实验室持续与工业界展开卓有成效的合作,与腾讯、阿里巴巴、苹果、微软、百度、快手、中兴通讯等多家知名企业开展项目合作和前沿探索,解决实际问题,进行科研成果的转化落地。

评论 0